
Existing methods for recovering depth for dynamics, non-rigid objects from monocular video impose strong assumptions on the object’s motion and may only recover sparse depth.
Google AI researchers said that they have picked up 2000 YouTube videos in which people imitate mannequins and used it as a data set to create an AI model that is capable of depth prediction from videos in motion. The applications of such an understanding could help developers craft augmented reality experiences in scenes shot with hand-held cameras and 3D video.
Researchers think this could provide the data set that helps detect the depth of the field in videos where the camera and people in the video are moving. In these videos, People imitate mannequins by freezing in a wide variety of natural poses while a hand-held camera tours the scene. And because the entire scene is stationary (only the camera is moving), triangulation-based methods- such as multi-view-stereo (MVS)- work. And the developers get accurate depth maps for the entire scene, including the people in it.
In the paper named ‘Learning the Depths of Moving People by Watching Frozen People’, the research team explained about applying a deep learning-based approach that can generate depth maps from an ordinary video, where both the camera and subjects are freely moving.
‘The model avoids direct 3D triangulation by learning priors on human pose and shape from data. While there is a recent surge in using machine learning for depth prediction, this work is the first to tailor a learning-based approach to the case of simultaneous camera and human motion.
In this work, the team focuses specifically on humans because they are an interesting target for augmented reality and 3D video’ as explained in the blog post. Google researchers said the approach outperforms state-of-the-art tools for making depth maps.
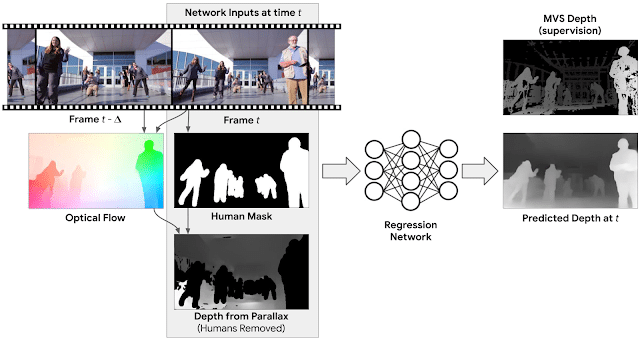
“To the extent that people succeed in staying still during the videos, we can assume the scenes are static and obtain accurate camera poses and depth information by processing them with structure-from-motion (SfM) and multi-view stereo (MVS) algorithms,” the paper reads. “Because the entire scene, including the people, is stationary, we estimate camera poses and depth using SfM and MVS and use this derived 3D data as supervision for training.”
The team trained a neural network that is capable of input from RGB images, a mask for human regions, and an initial depth of non-human environments in a video in order to produce a depth map and make the human shape and pose predictions